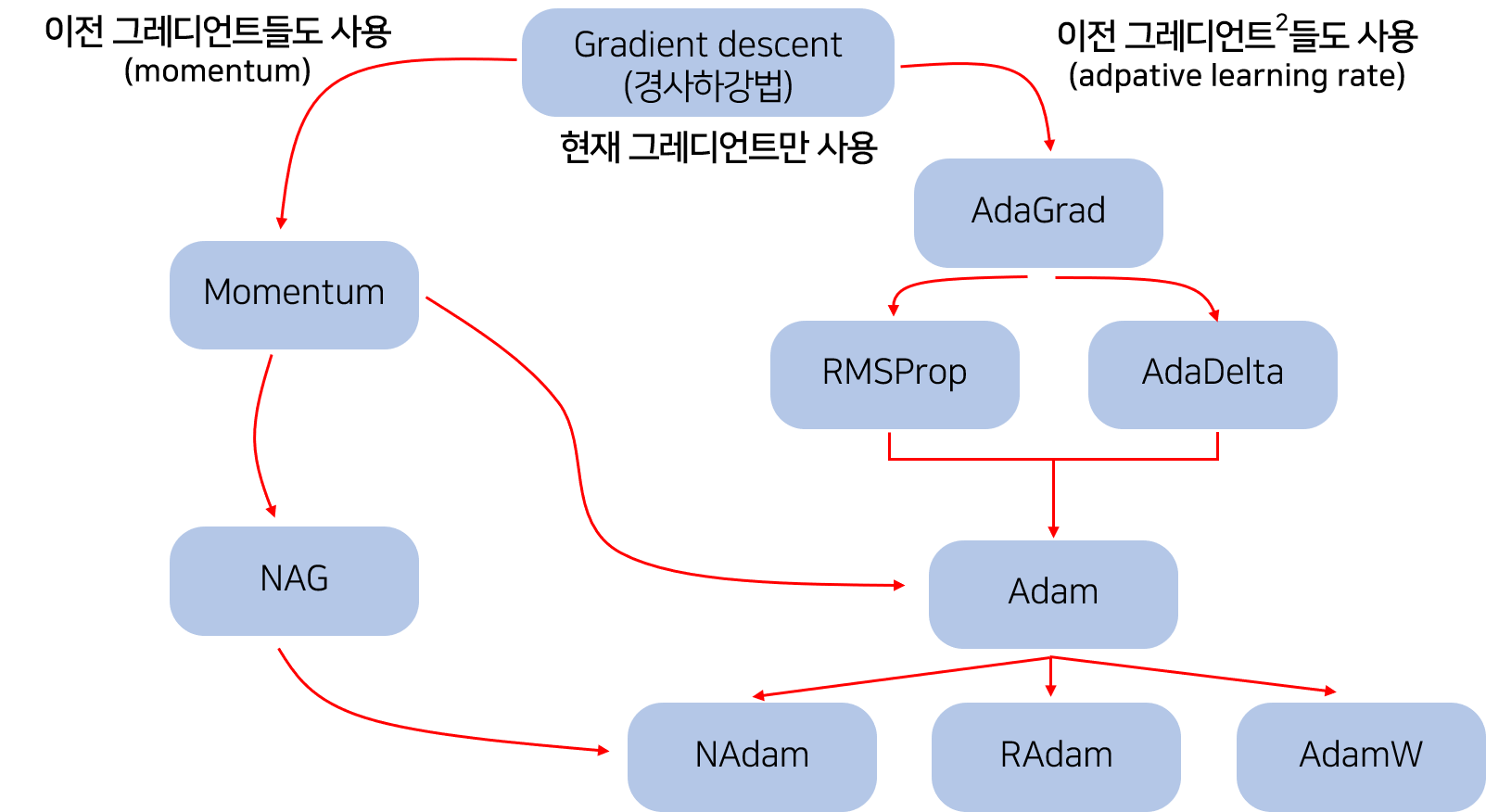
Gradient Descent(경사 하강법)
θt+1=θt−η∇θJ(θ)
- Batch gradient descent(BGD)
- Stochastic gradient descent(SGD)
- Mini-batch Stochastic gradient descent(MSGD)
- Momentum
SGD가 낮은 local minimum에서 벗어나 손실함수를 더 탐험할 수 있게 만들어 준다.
- NAG(Nesterov accelerated gradient)
NAG는 Momentum이 관성에 의해 수렴 지점에서 요동치는 것을 방지해 준다.
- Adagrad(Adaptive Gradient)
파라미터에 대해서 서로 다른 learning rate를 적용한다.
Adagrad는 parameter의 이전 gradient를 저장한다.
업데이트 빈도 수가 높았던 파라미터는 learning rate가 감소하게 된다.
t가 증가함에 따라 learning rate가 점점 소실되는 문제점이 있다.
- Adadelta
θt+1=θt+Δθt
Adagrad에서 발생한 iteration 마다 leearning rate가 작아지는 문제를 개선
- RMSprop
Adagra와 AdadeltaDML learning rate가 작아지는 문제를 개선
- Adam(Adaptive Moment Estimation)
Adagrad, Adadelta, RMSprop처럼 각 파라미터마다 다른 크기의 업데이트를 적용한다.
적절한 파라미터 값(default)
, ,
- AdaMax
Adam의 v_t 텀에 다른 norm을 사용
Adam과 다르게 max operation은 0으로의 편향이 없기 때문에 편향 보정을 해줄 필요가 없다.
θ
적절한 파라미터 값(default)
, ,
- NAdam(Nesterov-accelerated Adaptive Moment Adam)
NAdam은 Adam에 NAG의 momentum을 보완해주는 기능을 적용하였다.