과대적합(Overfitting)
과대 적합은 머신 러닝에서 자주 발생하는 문제이다.
모델이 훈련 데이터로는 잘 동작하지만 본적 없는 데이터(테스트데이터)로는 잘 일반화 되지 않는 현상이다.
(분산이 큼)
모델 파라미터가 너무 많아 주어진 데이터에서 너무 복잡한 모델을 만들기 때문이다.
과소적합(Underfitting)
훈련 데이터에 있는 패턴을 감지할 정도로 충분히 모델이 복잡하지 않다는 것을 의미한다.(높은 편향)

높은 편향은 과소적합에 비례하고 높은 분산은 과대적합에 비례한다.
분산: 모델을 여러번 훈련했을 때 특정 샘플에 대한 예측의 일관성(또는 변동성)을 측정
편향: 다른 훈련 데이터셋에서 여러 번 훈련했을 때 예측이 정확한 값에서 얼마나 벗어났는지 측정
좋은 편향-분산 트레이드오프를 찾기 위해서 모델의 복잡도를 조정해야 한다.
규제(regularization)
규제는 공선성(collinearity)을 다루거나 데이터에서 잡음을 제거함으로서
과대적합을 방지할 수 있는 매우 유용한 방법이다.
규제는 과도한 파라미터(가중치) 값을 제한하기 위해 추가적인 정보(편향)을 주입하는 개념이


L1 노름 & L2 노름
L2 규제
weights, params=[], []
for c in np.arange(-5, 5):
lr=LogisticRegression(C=10.**c, random_state=1, multi_class='ovr')
lr.fit(X_train_std, y_train)
weights.append(lr.coef_[1])
params.append(10.**c)
weights=np.array(weights)
plt.plot(params,weights[:,0], label='petal length')
plt.plot(params, weights[:,1],linestyle='--', label='petal width')
plt.ylabel('weight coefficient')
plt.xlabel('C')
plt.legend(loc='upper left')
plt.xscale('log')
plt.show()
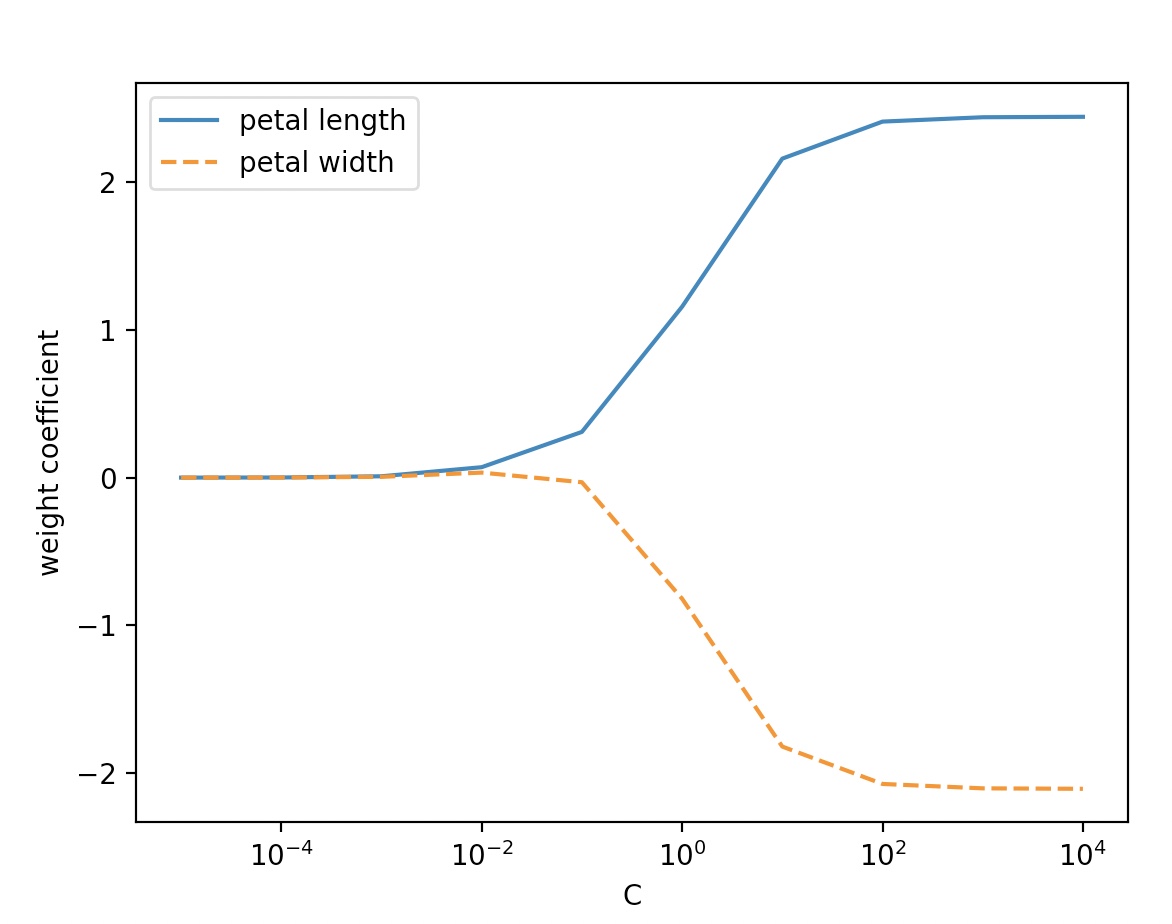
lambda는 C의 역수 이므로, 매개변수 C가 감소하면 가중치 절대값이 감소한다.
즉, 규제강도가 증가한다.