agent.py
from collections import defaultdict
import numpy as np
class Agent(object):
def __init__(self, env, learning_rate=0.01, discount_factor=0.9, epsilon_greedy=0.9, epsilon_min=0.1, epsilon_decay=0.95):
self.env=env
self.lr=learning_rate
self.gamma=discount_factor
self.epsilon=epsilon_greedy
self.epsilon_min=epsilon_min
self.epsilon_decay=epsilon_decay
self.q_table=defaultdict(lambda: np.zeros(self.env.nA))
def choose_action(self, state):
if np.random.uniform()<self.epsilon:
action=np.random.choice(self.env.nA)
else:
q_vals=self.q_table[state]
perm_actions=np.random.permutation(self.env.nA)
q_vals=[q_vals[a] for a in perm_actions]
perm_q_argmax=np.argmax(q_vals)
action=perm_actions[perm_q_argmax]
return action
def _learn(self, transition):
s, a, r, next_s, done=transition
q_val=self.q_table[s][a]
if done:
q_target=r
else:
q_target=r+self.gamma*np.max(self.q_table[next_s])
self.q_table[s][a]+=self.lr*(q_target-q_val)
self._adjust_epsilon()
def _adjust_epsilon(self):
if self.epsilon>self.epsilon_min:
self.epsilon*=self.epsilon_decay
qlearning.py
from gridworld_env import GridWorldEnv
from agent import Agent
from collections import namedtuple
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(1)
Transition=namedtuple('Transition', ('state', 'action', 'reward', 'next_state', 'done'))
def run_qlearning(agent, env, num_episodes=50):
history=[]
for episode in range(num_episodes):
state=env.reset()
env.render(mode='human')
final_reward, n_moves=0.0, 0
while True:
action=agent.choose_action(state)
next_s, reward, done, _=env.step(action)
agent._learn(Transition(state, action, reward, next_s, done))
env.render(mode='human', done=done)
state=next_s
n_moves+=1
if done:
break
final_reward=reward
history.append((n_moves, final_reward))
print('에피소드 %d: 보상 %.1f #이동 %d' %(episode, final_reward, n_moves))
return history
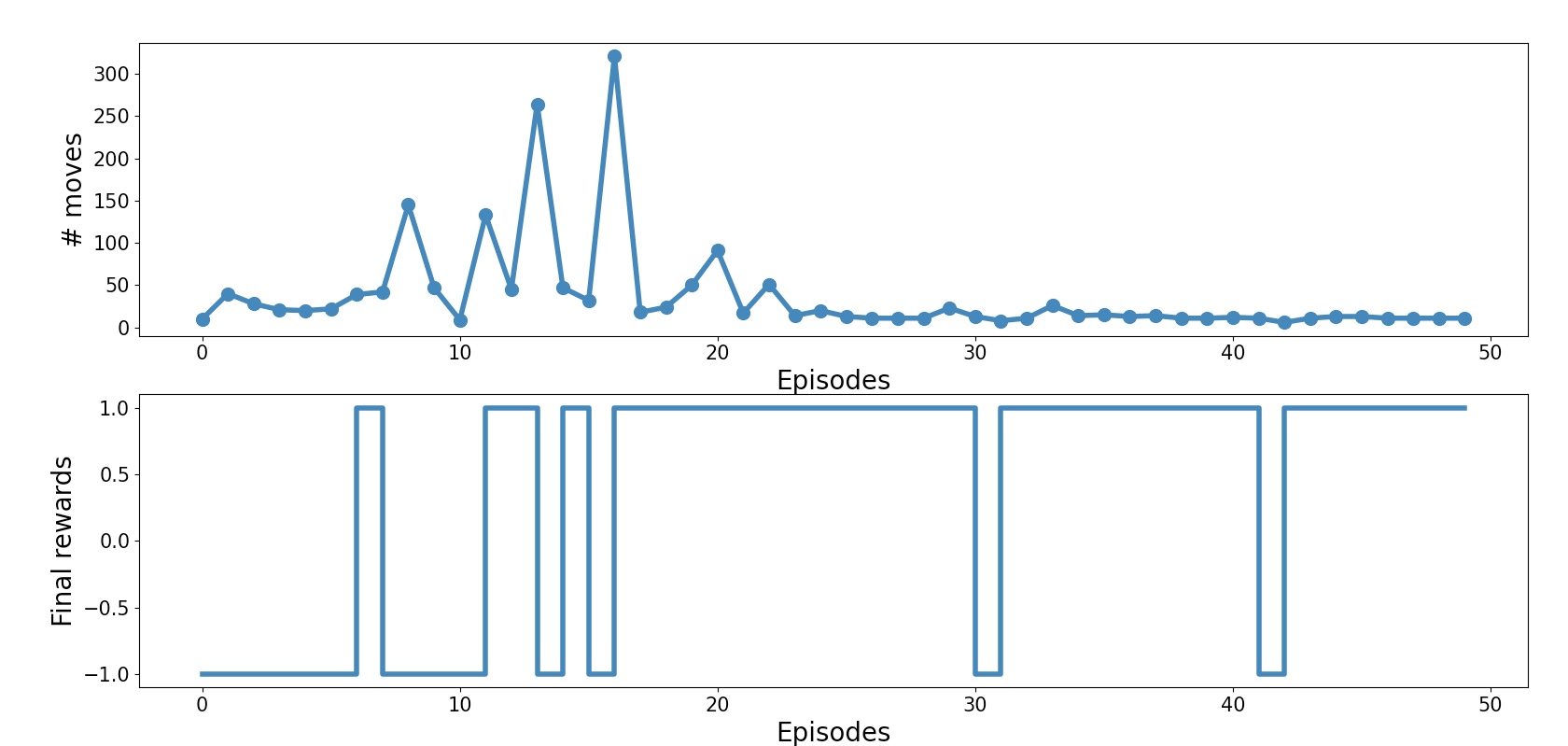
def plot_learning_history(history):
fig=plt.figure(1, figsize=(14, 10))
ax=fig.add_subplot(2, 1, 1)
episodes=np.arange(len(history))
moves=np.array([h[0] for h in history])
plt.plot(episodes, moves, lw=4, marker='o', markersize=10)
ax.tick_params(axis='both', which='major', labelsize=15)
plt.xlabel('Episodes', size=20)
plt.ylabel('# moves', size=20)
ax=fig.add_subplot(2, 1, 2)
rewards=np.array([h[1] for h in history])
plt.step(episodes, rewards, lw=4)
ax.tick_params(axis='both', which='major', labelsize=15)
plt.xlabel('Episodes', size=20)
plt.ylabel('Final rewards', size=20)
plt.savefig('q-learning-history.png', dpi=300)
plt.show()
if __name__=='__main__':
env=GridWorldEnv(num_rows=5, num_cols=6)
agent=Agent(env)
history=run_qlearning(agent, env)
env.close()
plot_learning_history(history)
GridWorld는 30(5x6)개의 이산적인 공간으로 되어 있기 때문에 Q-가치를 딕셔너리에 저장해도 충분하다.