머신러닝 알고리즘을 학습하기 다섯가지 주요 단계
1. 특성을 선택하고 훈련 샘플을 모은다.
2. 성능 지표를 선택한다.
3. 분류 모델과 최적화 알고리즘을 선택한다.
4. 모델의 성능을 평가한다.
5. 알고리즘을 튜닝한다.
Scikit-learn
사이킷런 라이브러리는 많은 학습 알고리즘을 제공할 분 아니라, 데이터 전처리나 세부 조정,
모델평가를 위해 편리하게 사용할 수 있는 함수를 포함하고 있다.
Perceptron with Scikit-learn
참고) 붓꽃 테스트는 간단하면서 인기많은 데이터 셋으로 Scikit-learn에 포함되어 있다.
from sklearn import datasets
import numpy as np
iris=datasets.load_iris()
X=iris.data[:,[2,3]]
y=iris.target
print("클래스 레이블:",np.unique(y))
클래스 레이블: [0 1 2]
Iris-setosa, Iris-versicolor, Iris-virginica는 이미 정수로 저장되어 있다.
클래스 레이블을 정수로 인코딩하는 것은 대부분 머신 러닝 라이브러리들의 공통된 관례이다.
훈련 데이터셋과 테슽트 데이터셋 분할
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test=train_test_split(X,y,test_size=0.3, random_state=1, stratify=y)
test data 30%(45개), train data 70%(105개) 로 분할
stratify=y를 통해 계층화(stratification)기능을 사용
이는 훈련 데이터셋과 테스트 데이터 셋의 클래스 레이블 비율을 입력 데이터셋과 동일하게 만든다.
print('y의 레이블 카운트:',np.bincount(y))
y의 레이블 카운트: [50 50 50]
print('y_train의 레이블 카운트:',np.bincount(y_train))
y_train의 레이블 카운트: [35 35 35]
print('y_test의 레이블 카운트:', np.bincount(y_test))
y_test의 레이블 카운트: [15 15 15]
특성 스케일 조정
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
sc.fit(X_train)
X_train_std=sc.transform(X_train)
X_test_std=sc.transform(X_test)
preprocessing 모듈에서 StandardScaler클래스를 이용해서 새로운 StandardScaler 객체를 sc변수에 할
당
transform 메서드를 호출해서 데이터셋을 표준화 한다.
사이킷런의 알고리즘은 대부분 기본적으로 OvR(One-versus-Rest) 방식을 사용하여,
다중 분류(multiclass classification)을 지원한다.
from sklearn.linear_model import Perceptron
ppn=Perceptron(eta0=0.1, random_state=1)
ppn.fit(X_train_std, y_train)
eta0는 학습률
mat_iter는 에포크 횟수를 정의한다.
분류오차(1-정확도)
학습 데이터셋으로 분류 후, 테이스 데이터셋을 이용한 테스트
y_pred=ppn.predict(X_test_std)
print('잘못 분류된 샘플 개수: %d' %(y_test!=y_pred).sum())
성능 지표
from sklearn.metrics import accuracy_score
print('정확도: %.3f' %accuracy_score(y_test, y_pred))
metrics 모듈 아래에는 다양한 성능 지표들이 구현되어 있다. 위는 정확도 측정 예시
사이킷런의 분류기 자체에도 정확도를 계산하는 score 메서드가 포함되어 있다.
print('정확도:%.3f' %ppn.score(y_test_std,y_test))
결정 경계 그리기
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
def plot_decision_regions(X,y, classifier, test_idx=None, resolution=0.02):
markers=('s','x','o', '^','v')
colors=('red','blue','lightgreen','gray','cyan')
cmap=ListedColormap(colors[:len(np.unique(y))])
x1_min,x1_max=X[:,0].min()-1, X[:,0].max()+1
x2_min,x2_max=X[:,1].min()-1, X[:,1].max()+1
xx1,xx2=np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution))
Z=classifier.predict(np.array([xx1.ravel(),xx2.ravel()]).T)
Z=Z.reshape(xx1.shape)
plt.contourf(xx1,xx2,Z,alpha=0.3, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y==cl, 0],y=X[y==cl,1],alpha=0.8, c=colors[idx], label=cl, edgecolor='black')
### add ###
if test_idx:
X_test, y_test=X[test_idx, :], y[test_idx]
plt.scatter(X_test[:,0],X_test[:,1], facecolors='none', edgecolor='black', alpha=1.0, linewidth=1, marker='o',s=100,label='test set')
X_combined_std=np.vstack((X_train_std, X_test_std))
y_combined=np.hstack((y_train, y_test))
plot_decision_regions(X=X_combined_std, y=y_combined, classifier=ppn, test_idx=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
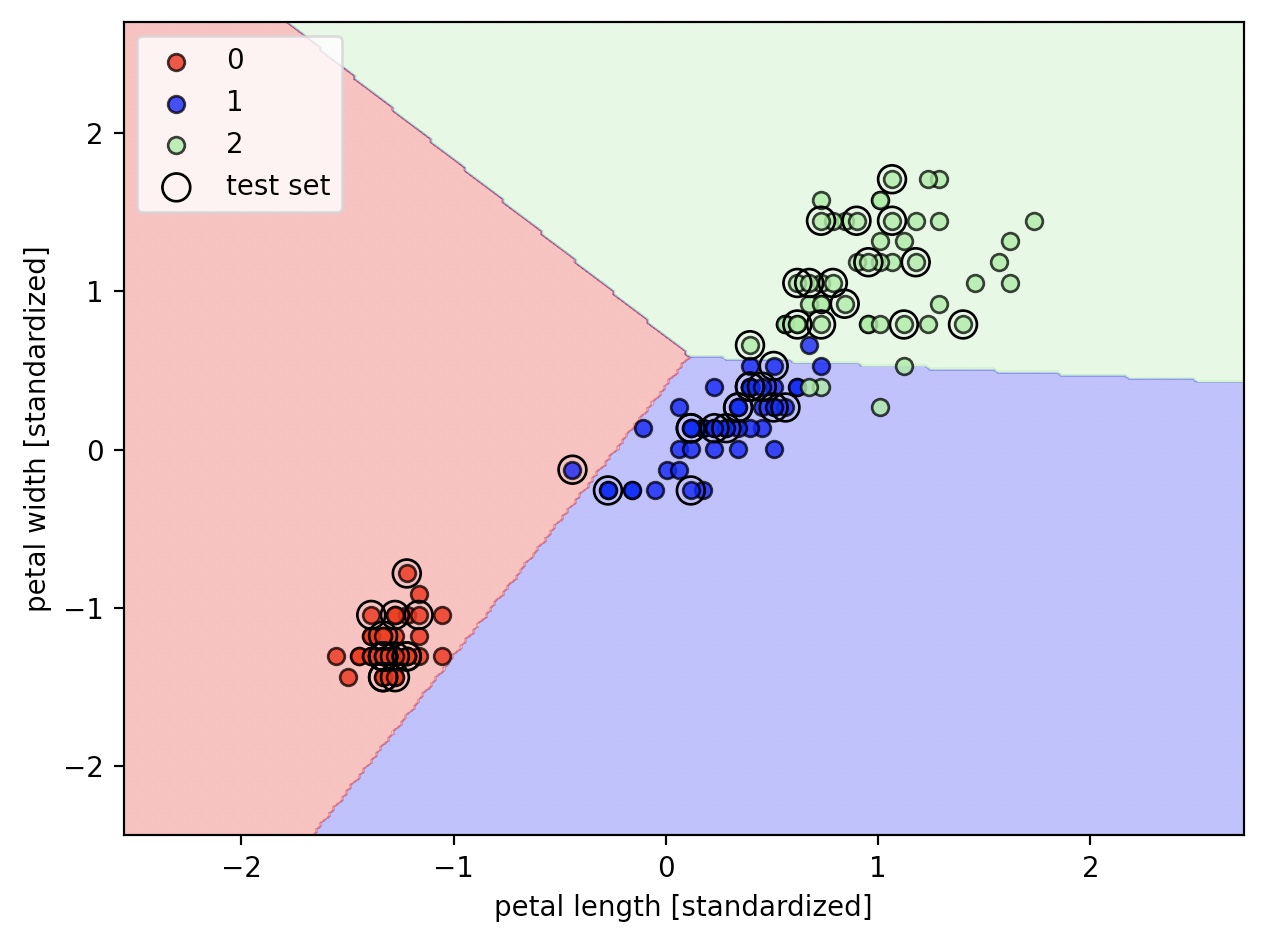
퍼셉트론은 선형적으로 구분하지 않는 데이터셋에 수렴하지 못한다.