기본적으로 Python은 GIL(Global Interpreter Lcok) 때문에 하나의 코어만 활용할 수 있다.
멀티 프로세싱 라이브러리를 사용해서 여러 개의 코어에 연산을 분산할 수 있지만, 16개 이상의 코어를 CPU가 가지기는 힘들다.
GIL
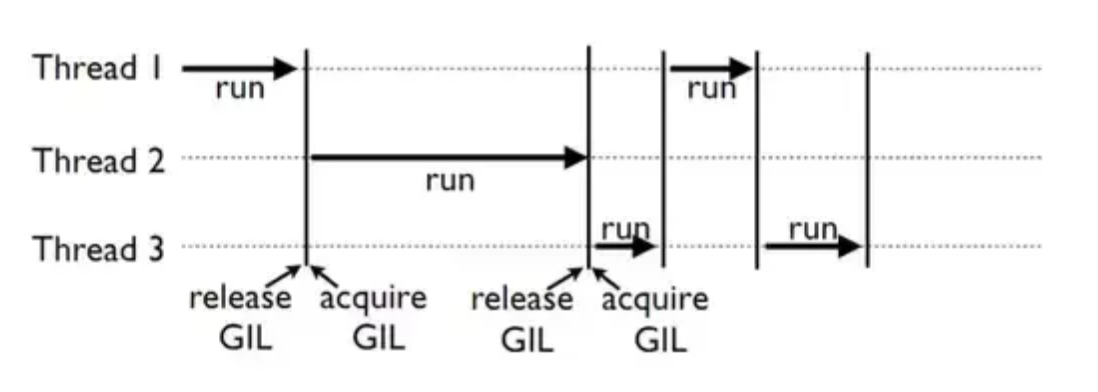
파이썬 인터프리터가 한 스레드만 하나의 바이트 코드를 실행시킬 수 있도록 Lock을 한다는 의미이다.
파이썬은 자바의 GC(Garbage Collector)가 아닌 Reference count를 이용해 동적메모리를 할당 해제한다.
import sys
a=[]
b=a
sys.getrefcount(a) //return 3
배열 []는 a, b, sys.getrefcount() 총 3개가 참조하고 있다.
reference count=0이 되면 메모리 할당 해제된다.
Java GC(Garbage Collector)
자바의 GC는 background에서 데몬 쓰레드로 돌면서 더이상 사용되지 않는 객체들을 메모리 해제하여, 효율적으로 메모리를 관리한다.
객체는 힙 영역에 저장되고, 스택 영역에 이를 가리키는 주소값이 저장되는데 참조되지 않는(자신을 가리키는 포인터가 없는, unreachable)
객체를 메모리에서 제거
만일 파이썬이 쓰레드를 허용할 시, 동시에 객체의 참조 카운트(refcount)를 수정할 수 있기 때문에 race condition이 발생한다.
refcount를 수정할 때마다, 모든 객체에 lock을 거는 것이 부담이고, 교착상태(deadlock)의 위험성이 있다.
따라서 python은 인터프리터를 통째로 Lock을 거는 방식을 사용한다.
모든 변수에 lock을 거는 것으로 인한 성능 저하는 없어지지만, CPU에 올라가는 프로그램을 Single-Threaded로 만든다
(쓰레드는 프로세스의 Stack영역을 제외하고는 공유한다.)
멀티프로세싱의 경우 경우 독립적인 프로세스 가상 메모리 공간이 존재하기 때문에 대체해서 사용 가능하다.(병렬 처리 가능)
CPU
AMD Ryzen 9 5900XCPU Cores: 12
CPU Thread: 24
Boost Cluck: Max 4.8GHz
Nor Cluck: 3.7GHz
Tot L2: 6MB
Tot L3: 64MB
GPU
GeForce GTX 1060 3GB
CPU Cores: 1152
Frame Buffer: 3GB GDDR5
Memory speed: 8Gbps
최신 GPU RTX 3080의 코어수가 10496임을 생각하면, 성능차이가 클것임
간단한 MNIST 분석의 다층 퍼셉트론(은닉층 100개의 유닛)의 경우 매우 단순한 이미지 분류작업을 위해 모델을 훈련하는데도
약 8만개의 가중치 파라미터([784X100+100]+[100X10+10]=79,450)를 최적화해야한다.
은닉층을 추가하고, 고해상도 이미지를 다룰 경우, 단일 프로세스로는 수행하기 어렵다.
GPU를 사용한 계산
GPU, 그래픽 카드를 컴퓨터 안에 포함된 작은 클러스터로 생각할 수 있다.
GPU에 맞는 코드를 작성하기 위해서는 CUDA나 OpenCL처럼 특정 GPU를 사용할 수 있도록 돕는 패키지가 필요하다.
텐서플로는 CUDA, OpenCL 코드 작성을 도울 수 있는 패키지이다.
텐서플로
텐서플로는 머신 러닝 알고리즘을 구현하고, 실행하기 위한 프로그래밍 인터페이스로 확장이 용이하고, 다양한 플랫폼을 지원한다.
딥러닝을 위한 간단한 인터페이스도 포함한다.
머신러닝 모델의 훈련 성능을 향상시키기 위해 텐서플로는 CPU와 GPU를 모두 활용한다.
텐서플로는 공식적으로 CUDA 기반의 GPU를 지원한다.(OpenCL은 실험적, 최근 M1칩에서 구동되는 텐서플로도 개발되었음)
텐서플로의 파이썬 API는 완전 성숙되어 있다.(C++도 공식적인 API 존재)
웹 브라우저와 IoT장치에 초점이 맞추어진, TensorFlow.js, TensorFlow.Lite도 공개되어 있다.
자바(Java), 하스켈(Haskell), Node.js, Go 같은 언어는 아직 API가 안정적이지 않다.
텐서플로는 노드(node)로 구성된 계산 그래프를 만든다.
각 노드는 0개 이상의 입력이나 출력을 가질 수 있는 연산을 표현한다.
심벌릭 핸들(symbolic handle)로 텐서(tensor)를 이용-넘파이 배열로 저장되고, 텐서는 참조를 제공
텐서플로는 정적인 계산 그래프와 2.0 부터는 유연성을 가진 동적인 계산 그래프를 기본으로 한다.
Install Tensorflow
pip3 install tensorflow
pip3 install tensorflow==[2.4.0] - 서적 텐서플로 버전
NVIDIA의 CUDA, cuDNN 라이브러리를 설치
pip3 install tensorflow-gpu
$python -c ‘import tensorflow as tf; print(tf.__version__)'